II - Quantifying Informativeness¶
Summary
On this page, we provide a primer on information theory.
Specifically, in section 1 - Quantifying Information we introduce the notions of Shannon, differential and mixed entropies, and we provide an intuition for why they are good measures of information content or uncertainty.
In section 2 - Association and Copula we introduce copulas, we discuss their importance for modeling associations, and we provide a fundamental identity relating the entropy of a random vector to the entropy of its copula and the entropies of its marginals.
Finally, in section 3 - Quantifying Association we introduce Shannon, differential and mixed mutual informations, we discuss their importance for quantifying associations between random variables, and we provide fundamental identities relating the differential or mixed mutual informations between two random variables and the associated copulas. In particular, we show that the differential mutual information between two random variables does not depend on their marginals.
Whether in the pre-learning or post-learning phase, a key to success is the ability to quantify how informative a vector of inputs \(x\) is about a label of \(y\). \(x\) can either be categorical, continuous, or have both categorical and continuous coordinates. \(y\) can either be continuous (in regression problems) or categorical (in classification problems).
As usual, we express our lack of knowledge and in-depth understanding about the dynamics of the phenomena giving rise to our inputs and/or label as randomness, and we model the inputs vector \(x\) and the label \(y\) as random variables.
Our approach to quantifying the information content of a random variable and how informative one random variable is about another is routed in information theory, of which we recall key notions below. For a more detailed exposition see [1] and [2].
1 - Quantifying Information¶
The canonical way of quantifying the information content of a probability distribution \(\mathbb{P}_x\) having density \(p\) with respect to a base measure \(\mu\) is its entropy, defined as
This notion extends to random variables in that the entropy of a random variable is, by definition, the entropy of its probability distribution
When the logarithm above is the natural logarithm, which will be the case throughout unless stated otherwise, the unit of the entropy is nats. When the binary logarithm is used instead, the entropy is expressed in bits.
a) Shannon Entropy¶
For a categorical random variable \(x\) taking \(q\) distinct values, the i-th with probability \(p_i\), the base measure is the counting measure, the density is the probability mass function (pmf) \(i \to p_i\), and the entropy reads
This special case was first introduced by Claude Shannon, the father of information theory, in his seminal work [3], and is often referred to in the litterature as Shannon entropy. Some of its properties are found below.
Properties
\(0 \leq H(x) \leq \log q\) for all categorical random variables.
\(H(x) = \log q\) if and only if \(x\) is uniform (i.e. \(\forall i, ~ p_i = 1/q\)).
\(H(x, y) \leq H(x) + H(y)\) for all categorical random variables \(x\) and \(y\).
\(H(x, y) = H(x) + H(y)\) if and only if \(x\) and \(y\) are statistically independent.
b) Differential Entropy¶
When the random variable \(x\) is continuous, takes values in \(\mathcal{C} \subset \mathbb{R}^d\), and its probability distribution admits density \(p\) with respect to the Lebesgue measure, its entropy, also referred to in the litterature as differential entropy, reads
The base measure in this case is the Lebesgue measure, and \(p\) is otherwise known as the probability density function (pdf) of \(x\).
The differential entropy enjoys much of the same properties as Shannon’s entropy, plus some scaling properties. A notable exception, however, is that it is not necessarily non-negative.
Properties
Let \(\text{Vol}(\mathcal{C}) = \int_{\mathcal{C}} dx\) denote the possibly infinite volume of the range of the distribution.
\(h(x) \leq \log \text{Vol}(\mathcal{C})\).
If \(\text{Vol}(\mathcal{C}) < +\infty\) then \(h(x) = \log \text{Vol}(\mathcal{C})\) if and only if \(x\) is uniform, i.e. \(p(x) = \mathbb{1} \left(x \in \mathcal{C} \right)/\text{Vol}(\mathcal{C})\).
\(h(x, y) \leq h(x) + h(y)\) for all continuous random variables \(x\) and \(y\).
\(h(x, y) = h(x) + h(y)\) if and only if \(x\) and \(y\) are statistically independent.
\(h(x + c) = h(x)\) for any deterministic constant \(c\).
\(h(Ax) = h(x) + \log |\text{det}(A)|\) for any deterministic invertible square matrix \(A\).
The fact that the differential entropy can be negative warrants a slight detour to provide an intuition for why it is an appropriate measure of information content.
c) Typical Sets¶
Let \(x^{(n)}\) be n i.i.d. draws from a (continuous or categorical) distribution \(\mathbb{P}_x\) with range \(\mathcal{C}\) and (Shannon or differential) entropy \(h(\mathbb{P}_x)\), and let \(p\left(x^{(n)}\right)\) their likelihood. It follows from the weak law of large numbers that \(-\frac{1}{n} \log p\left(x^{(n)}\right)\) converges in probability to \(h(\mathbb{P}_x)\), meaning that
Thus, if we define the sets
then for any \(\epsilon>0\), no matter how small, we can always find \(n\) large enough so that the full sequence \(x^{(n)}\) lies in \(\mathcal{A}_\epsilon^{(n)}\) with probability greater than \(1-\epsilon\),
As large enough sequences are very likely to belong to the sets \(\mathcal{A}_\epsilon^{(n)}\), these sets are called the typical sets of the distribution \(\mathbb{P}_x\). Moreover, the size of typical sets can be used as proxy for gauging the information content or variability of a distribution.
If we denote \(\text{Vol}\left( \mathcal{A}_\epsilon^{(n)}\right)\) the volume (resp. cardinality) of \(\mathcal{A}_\epsilon^{(n)}\) when \(\mathbb{P}_x\) is continuous (resp. categorical), then it can be shown that [*] for any \(\epsilon > 0\) and for any large enough \(n\)
Given that we can choose \(\epsilon\) arbitrarily small, it follows from inequalities (4) that the information content of a continuous (resp. categorical) distribution or random variable increases with its differential (resp. Shannon) entropy.
Consequently, the differential entropy, even when negative, measures the information content of a random variable. In fact, \(e^{nh\left(\mathbb{P}_x \right)}\) can be interpreted as the number of nats [†] required to encode the sequence \(x^{(n)}\), whether the distribution is categorical or continuous.
d) Conditional Entropy¶
In case a random variable \(x \in \mathcal{C}_x\) is suspected to be informative about another random variable \(y \in \mathcal{C}_y\), one might want to quantify the extent to which knowing \(x\) affects our uncertainty about, or the information content of \(y\). If \(x\) and \(y\) are either both continuous or both categorical, the conditional entropy, defined as
quantifies the information content of (or the amount of uncertainty about) \(y\) that remains despite knowing \(x\).
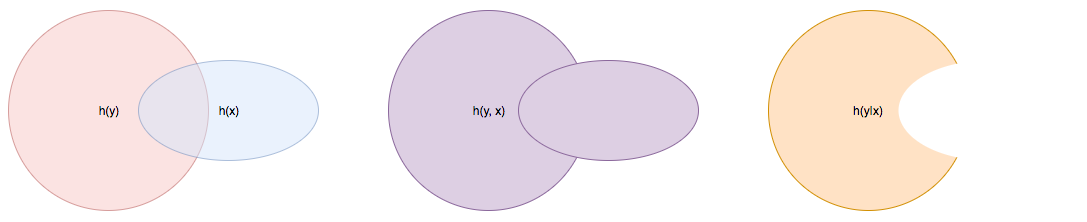
Fig 1. Venn diagram illustrating joint and conditional entropies.¶
A direct consequence of property P3 above is that, both in the case of categorical and continuous random variables, \(h\left(y \vert x \right) \leq h(y)\). Said differently, knowning the value of a random variable \(x\) cannot increase our uncertainty about, or the information content of random variable \(y\). Moreover, it follows from P4 that knowning the value of a random variable \(x\) leaves the uncertainty about \(y\) unchanged if and only if \(x\) and \(y\) are statistically independent.
Going forward and without lack of generality, when a categorical random variable takes \(q\) distinct values, we will assume these values are \(1, \dots, q\).
A useful insight in the conditional entropy is provided by its linked to conditional distributions. We recall that the conditional distribution of \(y\) given a specific value of \(x\), which we denote \(y|x=*\) is the distribution with pmf
when \(x\) and \(y\) are both categorical, or the distribution with pdf
when \(x\) and \(y\) are both continuous.
As its name suggests, the conditional distribution models the behavior of \(y\) after a specific value \(*\) of \(x\) has been observed, irrespective of how likely said value is. Its entropy \(h\left(y \vert x=* \right)\) is a function of the observed value of \(x\), and it turns out that the average value of \(h\left(y \vert x=* \right)\) weighted by how likely the value \(*\) is, happens to be the conditional entropy
e) Mixed Entropy¶
It follows from Equations (5) and (6) that
when \(x\) and \(y\) are either both continuous or both categorical.
When one variable is categorical (for instance \(y\)), and the other continuous (for instance \(x\)), the joint distribution of \((x, y)\) is fully defined through the pmf of \(y\), namely \(\mathbb{P}(y=i) := p_i\), and the \(q\) conditional pdfs \(p\left(x \vert y=i \right)\).
In such a case, the entropy can be evaluated from Equation (1) using as base measure space the product of the Lebesgue measure space and \(\mathbb{Z}\) endowed with the counting measure, using as base measure the induced measure, and by working out the induced density function.
Alternatively, the entropy can also be obtained by applying the result in Equation (7):
2 - Association and Copula¶
Another important mathematical construct in the study of associations between continuous random variables are copulas.
Let \(x = (x_1, \dots, x_d) \in \mathcal{C} \subset \mathbb{R}^d\) be a continuous random variable, \(F\) its cummulative density function (cdf) and \(F_i\) the cdf of its i-th coordinate \(x_i\). It can be shown that \(u_i := F_i(x_i)\), also denoted the probability integral transform of \(x_i\), is uniformly distributed on \([0, 1]\).
We refer to
as the copula-uniform dual representation of \(x\), and we denote \(C\) (resp. \(c\)) the cdf (resp. pdf) of \(u\).
Note
\(C\) is called the copula of \(x\). More generally, a copula is any mathematical function that is the cdf of a distribution with uniform marginals.
a) Sklar’s Theorem¶
It is worth pointing out that, as stated by Sklar’s theorem, every multivariate cdf can be expressed in terms of its copula and its marginals in the following way
and the copula \(C\) is the only function satisfying such as a decomposition when the marginals \(F_i\) are continuous. Thus, while marginals \(u_i\) are all standard uniform, their joint distribution fully reflects the dependence structure between coordinates of \(x\).
b) Copula and Structure¶
We note that any strictly increasing transformation on coordinates \(x_i\) would change their marginals but would leave their copula invariant when the marginals \(F_i\) are continuous.
Indeed, if \(f_i\) are \(d\) increasing transformations and \(y := \left(f_1(x_1), \dots, f_d(x_d)\right)\) whith cdf \(G\), then we have
which by Sklar’s theorem implies that \(C\) is also the copula of \(y\).
This result is very important because it provides a sense in which marginal distributions solely reflect how the underlying phenomena were observed or used datasets were prepared (e.g. standardizing or not, taking the logarithm or not, squashing through a sigmoid-like function or not etc.), whereas the copula fully captures the dependence structure in the underlying phenomena irrespective of how they were observed.
Important
Marginals are a property of data vendors and data teams, copulas characterize the structure in your problem. You should study your problem, not your data vendor.
Another perspective on why copulas capture association between random variables is provided by the expression of the copula density \(c\) as a function of the joint and marginal primal densities:
The copula density is the ratio of the actual joint (resp. conditional) density, and the hypothetical joint (resp. conditional) density had there been no association betweeen coordinates.
Moreover, the copula-uniform dual distribution is the uniform distribution on the hypercube \([0, 1]^d\) if and only if coordinates \(x_i\) are statistically independent.
c) Entropy Decomposition¶
It follows from Equation (9) that the entropy of a continuous random variable \(x\) can be broken down as the sum of the entropies of its marginals and the entropy of its copula-uniform dual representation,
Property
This Equation is fundamental as it allows us to break down the estimation of the entropy of \(x\) in two stages: estimating the entropy of its marginals when it is really needed, and estimating the entropy of its copula. As we will see later, both stages are easier to solve than directly estimating the entropy of \(x\) and, in many cases, the entropies of marginals will cancel each other out in informativeness metrics.
3 - Quantifying Association¶
If the entropy is the canonical measure of information content, and copulas the canonical approach for modeling associations between random variables, the mutual information is the canonical approach for quantitying associations between random variables.
a) Mutual Information¶
In plain english, the mutual information between random variables \(x\) and \(y\), denoted \(I(x; y)\), is the information content of \(x\) that relates to \(y\) or, equivalently, the information content of \(y\) that relates to \(x\). It is formally defined as
One of the most important properties of mutual information is that it is invariant by invertible transformations. [‡]
Property
Let \(x\) and \(y\) be two random variables, and let \(f\) and \(g\) be two invertible functions defined on the ranges of \(x\) and \(y\) respectively. Then
b) Conditional Mutual Information¶
Similarly, we can define the condition mutual information between random variables \(x\) and \(y\) given a third random variable \(z\) as the information content of \(x\) that relates to \(y\) (or equivalently the information content of \(y\) that relates to \(x\)) when \(z\) is known:
Note
It follows from the equation above that the conditional mutual information is the expected value of the mutual information between the conditional distributions \(x \vert z=*\) and \(y \vert z=*\)
c) Mutual Information and Copula¶
When \(x\) and \(y\) are both continuous, we can use Equation (10) to show that the mutual information between \(x\) and \(y\) is in fact unrelated to their marginal distributions, and is simply equal to the mutual information betweeen their copula-uniform dual representations.
Property
Note
When either \(x\) or \(y\) is one-dimensional, the associated copula-uniform dual representation is uniformly distributed on \([0, 1]\) and has entropy 0.
When one of the two variables is categorical, for instance \(y\), and the other multidimensional and continuous, the mutual information between \(x\) and \(y\) can be broken down as the sum of the mutual information between \(y\) and the copula-uniform representation of \(x\) and the mutual information between coordinates \(x_i\) and \(y\).
Property
When \(x\) is continuous with copula-uniform dual representation \(u\) and \(y\) is categorical,
A similar result can be obtained for the mutual information between \((x, z)\) and \(y\) when \(x\) is continuous and \(z\) and \(y\) are categorical.
Property
When \(x\) is continuous with copula-uniform dual representation \(u\), and \(y\) and \(z\) are categorical,
Finally, we provide the result when \(x\) and \(y\) are continuous and \(z\) is categorical.
Property
When \(x\) and \(y\) are continuous with copula-uniform dual representations \(u_x\) and \(u_y\), and \(z\) is categorical,
d) Quantifying Informativeness¶
Now that we are equipped with the right tools, we can answer the question that is central to pre-learning and post-learning: how informative are a collection of inputs \(x\) about a label \(y\)?
Important
Given two random variables, the extent to which one is informative about the other can be quantified using their mutual information. When both variables are categorical, Equation (11) is used and individual entropy terms are Shannon entropies (Equation (2)). When both variables are continuous, Equation (14) is used. When one variable is continuous and the other categorical, Equation (15) is used. When one variable is categorical and the other has continuous and categorical coordinates, Equation (16) is used. Finally, when one variable is continuous and the other has continuous and categorical coordinates, Equation (17) is used.
References
- 1(1,2,3)
Cover, T.M. and Thomas, J.A., 2012. Elements of information theory. John Wiley & Sons.
- 2
Ihara, S., 1993. Information theory for continuous systems (Vol. 2). World Scientific.
- 3
Shannon, C.E., 1948. A mathematical theory of communication. Bell system technical journal, 27(3), pp.379-423.
Footnotes
- *
See Theorem 9.2.2 in [1].
- †
\(1 \text{nat} = (1/\log2) \text{bits} \approx 1.44 \text{bits}\)
- ‡
Hint: Use Definition (8.54) in [1] and note that there is a one-to-one map between partitions of the range of \(x\) (resp. \(y\)) and partitions of the range of \(f(x)\) (resp. \(g(y)\)), and that the mutual informations of the associated quantized variables are the same.